Siber Güvenlikte Yapay Zeka Uygulamaları: Makale İncelemesi
Large Language Model for Vulnerability Detection and Repair: Literature Review and the Road Ahead
Güvenlik Açığı Tespiti ve Onarımı için Büyük Dil Modeli: Literatür İncelemesi ve Geleceğe Yönelik Yol Haritası
RESEARCH-ARTICLE / Araştırma Makalesi XIN ZHOU, Singapore Management University, Singapore City, Singapore SICONG CAO, Yangzhou University, Yangzhou, Jiangsu, China XIAOBING SUN, Yangzhou University, Yangzhou, Jiangsu, China DAVID LO, Singapore Management University, Singapore City, Singapore Open Access Support provided by: Singapore Management University Yangzhou University https://dl.acm.org/doi/10.1145/3708522 | 27 Mayıs 2025 tarihinde yayınlandıKonular:
-
Tanım
-
Literatürdeki Boşluğu Doldurması
-
Tespit ve Onarımı Birlikte Ele Alması
-
Yöntemsel ve Deneysel Sınırlamaları Görünür Kılması
-
Gelecek Araştırmalar için Yol Haritası Sunması
-
Yöntem
-
Problem
-
Ele Alınan Senaryo/Tehdit/Açık
-
Araştırma Sorularının Tanımlanması
-
Literatür Tarama Süreci
-
Çalışma Tanımlama ve Seçim Süreci
Giriş
İçerik
Araştırma Soruları (RQ*1/2/3/4) ve Sonuç
Merhabalar. Siber Güvenlikte Yapay Zeka Uygulamaları dersimiz kapsamında bugün yukarıda bilgileri belirtilmiş olan makalenin incelemesini ve değerlendirmesini gerçekleştireceğiz.
Giriş
Bu makale, büyük dil modellerinin (Large Language Models – LLM’ler) yazılım güvenliği alanında, özellikle güvenlik açığı tespiti (vulnerability detection) ve güvenlik açığı onarımı (vulnerability repair) görevlerinde kullanımını ele alan ilk kapsamlı ve sistematik literatür incelemelerinden biridir. Çalışma, son yıllarda hızla artan LLM tabanlı yaklaşımları dağınık ve parçalı hâlde sunan literatürü bir araya getirerek, alanın mevcut durumunu bütüncül bir çerçeve içinde değerlendirmektedir.
Makalenin önemi birkaç temel noktada toplanmaktadır:
Literatürdeki Boşluğu Doldurması
Daha önceki çalışmalar genellikle tekil modeller, belirli veri setleri veya dar kapsamlı deneysel sonuçlar üzerinden ilerlerken, bu makale LLM’lerin güvenlik açığı bulma ve onarma süreçlerindeki rollerini sistematik biçimde sınıflandırarak karşılaştırmalı bir perspektif sunmaktadır. Bu yönüyle, alan için bir referans çalışması niteliği taşır.Tespit ve Onarımı Birlikte Ele Alması
Mevcut literatürün büyük kısmı güvenlik açıklarının yalnızca tespitine odaklanırken, bu makale otomatik onarım (repair) konusunu da aynı çerçevede inceleyerek, LLM’lerin yazılım güvenliğinde uçtan uca (end-to-end) kullanım potansiyelini tartışmaktadır.Yöntemsel ve Deneysel Sınırlamaları Görünür Kılması
Çalışma, LLM tabanlı yaklaşımların mevcut başarılarına ek olarak; veri seti çeşitliliği, değerlendirme metriklerinin standardize edilmemesi, model genellenebilirliği ve güvenilirlik gibi kritik metodolojik sorunları açık biçimde ortaya koymaktadır. Bu, alandaki sonuçların neden temkinli yorumlanması gerektiğini göstermesi açısından önemlidir.Gelecek Araştırmalar için Yol Haritası Sunması
Makale, yalnızca mevcut çalışmaları özetlemekle kalmayıp, LLM’lerin yazılım güvenliğinde daha etkili ve güvenilir şekilde kullanılabilmesi için somut araştırma yönelimleri ve açık problemler tanımlamaktadır. Bu yönüyle, yeni çalışma yapacak araştırmacılar için stratejik bir rehber işlevi görür.Yöntem
Bu makale sistematik literatür incelemesi (Systematic Literature Review – SLR) yöntemini benimsemektedir. Amaç, LLM’lerin yazılım güvenlik açıklarını tespit etme ve onarma alanındaki mevcut çalışmalarını tarafsız, tekrarlanabilir ve kapsayıcı bir şekilde analiz etmektir.Problem
Büyük dil modellerinin (LLM’lerin) yazılım güvenliği alanında, özellikle güvenlik açığı tespiti ve onarımı için giderek daha fazla kullanılmasına rağmen;
- Bu alandaki çalışmaların dağınık, parçalı ve karşılaştırılması zor olması,
- Kullanılan yöntemlerin, modellerin ve değerlendirme ölçütlerinin standartlaşmamış olması,
- LLM’lerin gerçekten ne kadar etkili, güvenilir ve genellenebilir olduğuna dair
bütüncül ve sistematik bir anlayışın eksik olması
Ele Alınan Senaryo/Tehdit/Açık
Makale, belirli bir siber tehdidi veya tekil bir güvenlik açığını incelemekten ziyade, büyük dil modellerinin yazılım güvenlik açıklarını genel bir problem alanı olarak tespit etme ve onarma yetkinliğini ele alan sistematik bir literatür incelemesidir.İçerik
Araştırma Sorularının Tanımlanması
Çalışma, literatürü yönlendirmek için 4 adet(Research Questions - RQ*1/2/3/4) açık araştırma sorusu belirlemiştir.
- Hangi LLM türleri güvenlik açığı tespiti ve onarımında kullanılıyor?
- LLM'ler güvenlik açığı tespiti için nasıl uyarlanıyor?
- LLM'ler güvenlik açığı onarımı için nasıl uyarlanıyor?
- LLM tabanlı güvenlik açığı tespiti ve onarımı çalışmalarında kullanılan
veri kümelerinin ve dağıtım stratejilerinin özellikleri nelerdir?
Literatür Tarama Süreci
Hakemli dergiler, konferanslar ve yüksek kaliteli preprint çalışmalar sistematik biçimde taranmıştır. Belirli dahil etme/dışlama kriterleri uygulanarak alakasız veya düşük kaliteli çalışmalar elenmiştir. Sonuçta, LLM’lerin yazılım güvenliğinde kullanımına odaklanan sınırlı ama temsil gücü yüksek bir çalışma kümesi oluşturulmuştur.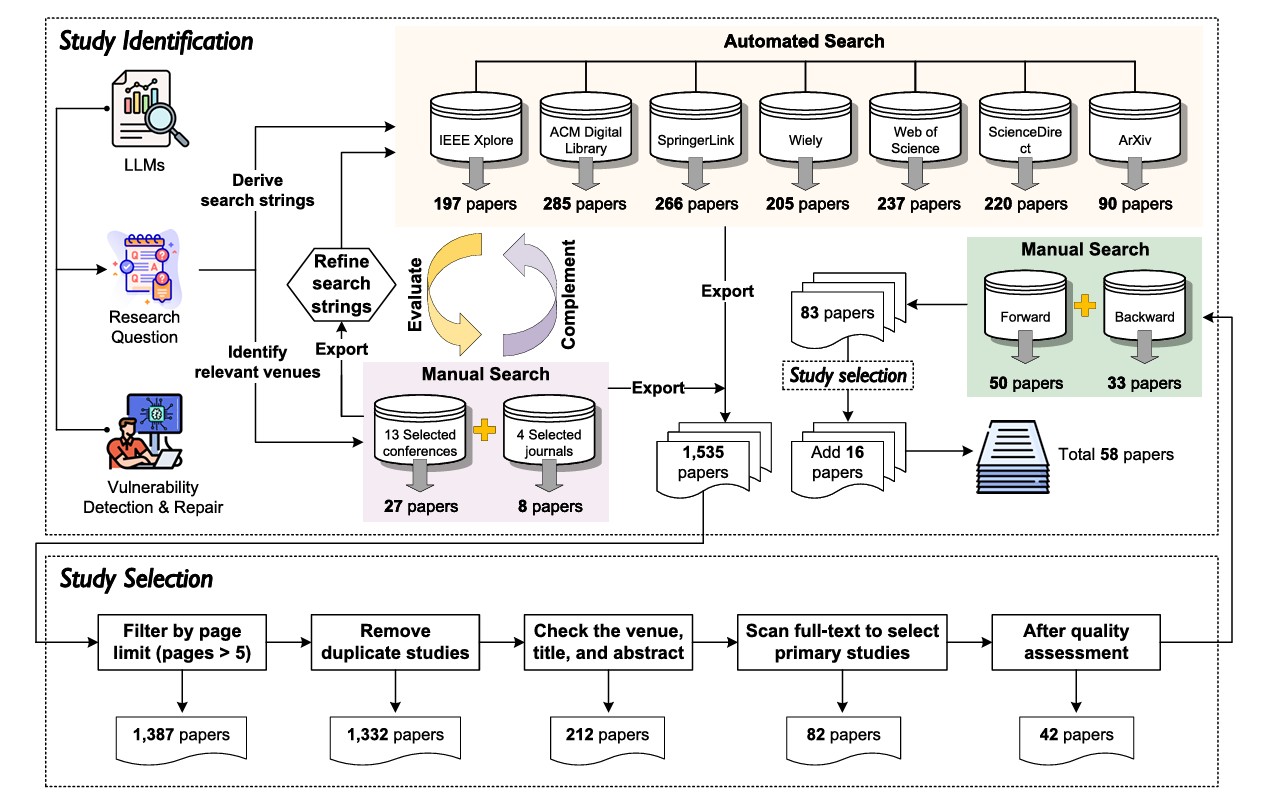
Çalışma Tanımlama ve Seçim Süreci
Makalelerin toplanmasının ardından, aşağıdaki dahil etme ve hariç tutma kriterlerine göre bir uygunluk değerlendirmesi yapılmıştır:Araştırma Soruları (RQ*1/2/3/4) ve Sonuç
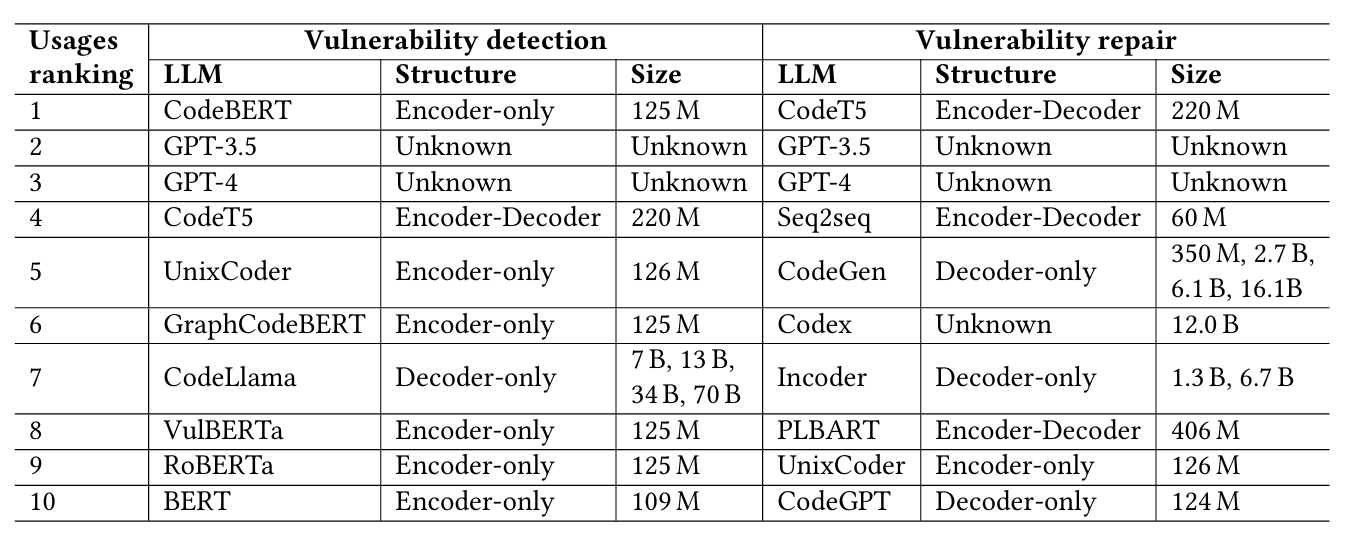
RQ1 - Hangi LLM türleri güvenlik açığı tespiti ve onarımında kullanılıyor?
Makalede güvenlik açığı tespitinde ve onarımında kullanılan LLM Türleri aşağıdaki tabloya göre ele alınmıştır. Güvenlik Açığı Tespiti ve Onarımında Kullanılan En İyi 10 Büyük Dil Modeli (LLM);LLM’lerde Encoder ve Decoder Kavramları
Large Language Model (LLM) mimarilerinde encoder ve decoder terimleri, modelin girdiyi nasıl işlediğini ve çıktıyı nasıl ürettiğini tanımlayan temel bileşenlerdir. Bu kavramlar Transformer mimarisine dayanır.
1. Encoder Nedir?
Encoder, girdi metnini alarak onu bağlamsal ve sayısal temsillere (embedding’lere) dönüştüren model bileşenidir. Encoder’ın temel amacı metni anlamaktır.
Encoder’ın Görevleri
- Metni token’lara ayırmak
- Self-attention mekanizması ile token’lar arasındaki ilişkileri hesaplamak
- Her token için bağlamı içeren vektör temsilleri üretmek
Girdi: “Bugün hava çok güzel”
Çıktı: Her kelimenin bağlamını içeren vektör temsilleri
Encoder tabanlı modeller genellikle metin üretmez; sınıflandırma ve anlamsal analiz gibi görevlerde kullanılır.
Encoder ağırlıklı modellere örnekler:
- BERT
- RoBERTa
- DistilBERT
2. Decoder Nedir?
Decoder, önceki token’lara bakarak bir sonraki token’ı tahmin eden ve metin üreten model bileşenidir. Decoder’ın ana amacı çıktı üretmektir.
Decoder’ın Görevleri
- Önceki token’ları dikkate almak (masked self-attention)
- Bir sonraki en olası token’ı tahmin etmek
- Akıcı ve bağlama uygun metin üretmek
Girdi: “Bugün hava”
Çıktı: “çok güzel”
Günümüzdeki çoğu sohbet ve üretim odaklı LLM, yalnızca decoder mimarisi kullanır.
Decoder ağırlıklı modellere örnekler:
- GPT serisi
- LLaMA
- Mistral
3. Encoder–Decoder Mimarisi
Bazı modellerde encoder ve decoder birlikte kullanılır. Bu yaklaşımda:
- Encoder girdiyi temsil eder ve anlar
- Decoder bu temsili kullanarak çıktı üretir
Makine çevirisi
Encoder: Kaynak dili işler
Decoder: Hedef dilde çeviriyi üretir
Encoder–Decoder mimarisi kullanan modellere örnekler:
- T5
- BART
- MarianMT
 RQ1 sorusuna yanıt:
Bugüne kadar güvenlik açığı tespitinde ağırlıklı olarak yalnızca kodlayıcı (encoder-only) LLM’lerin kullanıldığını; buna karşılık güvenlik açığı onarımında ticari LLM’lerin ve yalnızca çözücü (decoder-only) LLM’lerin öne çıktığı görülmektedir.
RQ1 sorusuna yanıt:
Bugüne kadar güvenlik açığı tespitinde ağırlıklı olarak yalnızca kodlayıcı (encoder-only) LLM’lerin kullanıldığını; buna karşılık güvenlik açığı onarımında ticari LLM’lerin ve yalnızca çözücü (decoder-only) LLM’lerin öne çıktığı görülmektedir.
RQ2 - LLM'ler güvenlik açığı tespiti için nasıl uyarlanıyor?
Makalede LLM’lerin güvenlik açığı tespitindeki özel adaptasyon teknikleri aşağıdaki çeşitlere göre incelenmiştir. (1) Bir veri kümesi kullanılarak LLM parametrelerinin güncellendiği ince ayar (fine-tuning) (2) Parametreler güncellenmeden, LLM’lerin ilgili çıktılar üretmesini yönlendirmek amacıyla istemlerin tasarlandığı istem mühendisliği (prompt engineering) (3) Yine LLM parametreleri değiştirilmeden, performansı artırmak için geri getirim sistemlerinden elde edilen bilginin LLM bağlamına entegre edildiği getirim artırma (retrieval augmentation – RAG) Fine-tuning (İnce Ayar), önceden büyük ve genel amaçlı veri kümeleri üzerinde eğitilmiş bir Büyük Dil Modelinin (LLM), belirli bir görev veya alan için yeniden uyarlanması sürecidir. Prompt engineering (İstem Mühendisliği), Büyük Dil Modellerinin (LLM) davranışını ve ürettiği çıktıları, modelin parametrelerini değiştirmeden, yalnızca verilen girdinin (istem/prompt) dikkatli ve sistematik biçimde tasarlanması yoluyla yönlendirme tekniğidir. Retrieval Augmentation (RAG – Getirim Artırma), Büyük Dil Modellerinin (LLM) performansını artırmak amacıyla, model parametrelerini değiştirmeden, harici bilgi kaynaklarından geri getirilen (retrieved) ilgili bilgilerin modelin girdisine entegre edilmesi esasına dayanan bir uyarlama tekniğidir.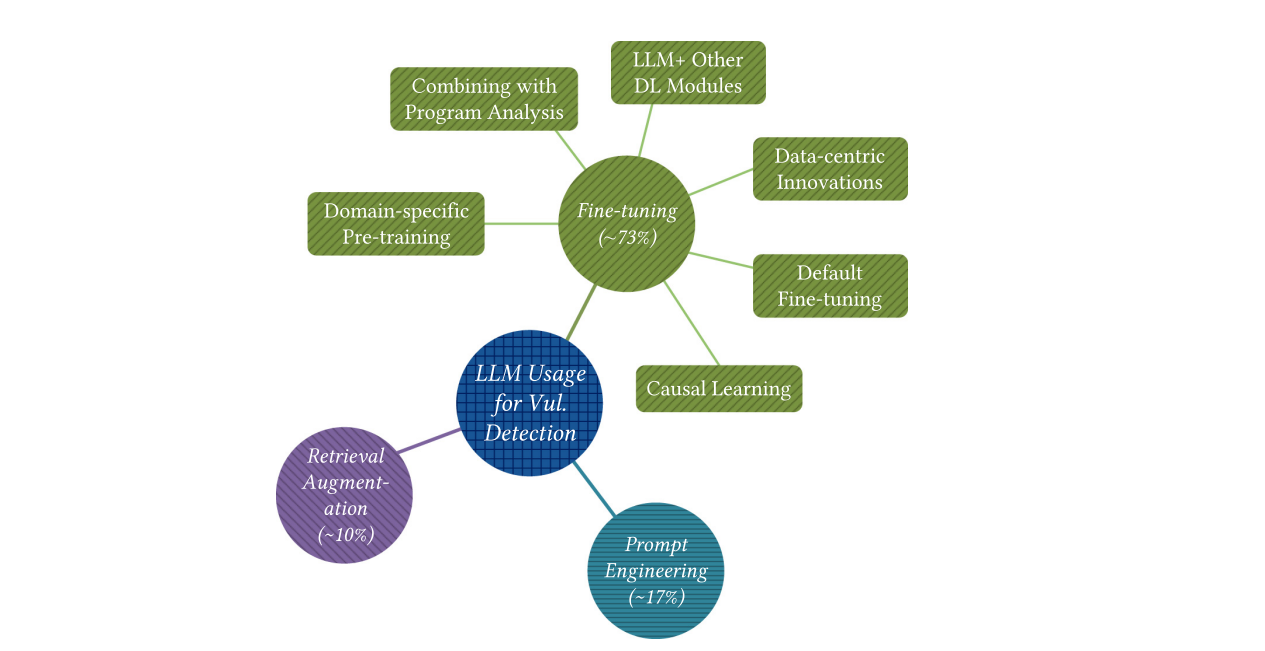 RQ2 sorusuna yanıt:
LLM’lerin güvenlik açığı tespitine uyarlanmasında yaygın olarak kullanılan üç temel teknik mevcuttur: ince ayar (fine-tuning) (≈%73), istem mühendisliği (prompt engineering) (≈%17) ve getirim artırma (retrieval augmentation, RAG) (≈%10).
RQ2 sorusuna yanıt:
LLM’lerin güvenlik açığı tespitine uyarlanmasında yaygın olarak kullanılan üç temel teknik mevcuttur: ince ayar (fine-tuning) (≈%73), istem mühendisliği (prompt engineering) (≈%17) ve getirim artırma (retrieval augmentation, RAG) (≈%10).
RQ3 - LLM'ler güvenlik açığı onarımı için nasıl uyarlanıyor?
Makalede LLM’lerin güvenlik açığı onarımındaki özel adaptasyon teknikleri, tespitte yer alan RAG tekniği hariç tutularak yine aşağıdaki çeşitlere göre incelenmiştir. (1) Bir veri kümesi kullanılarak LLM parametrelerinin güncellendiği ince ayar (fine-tuning) (2) Parametreler güncellenmeden, LLM’lerin ilgili çıktılar üretmesini yönlendirmek amacıyla istemlerin tasarlandığı istem mühendisliği (prompt engineering)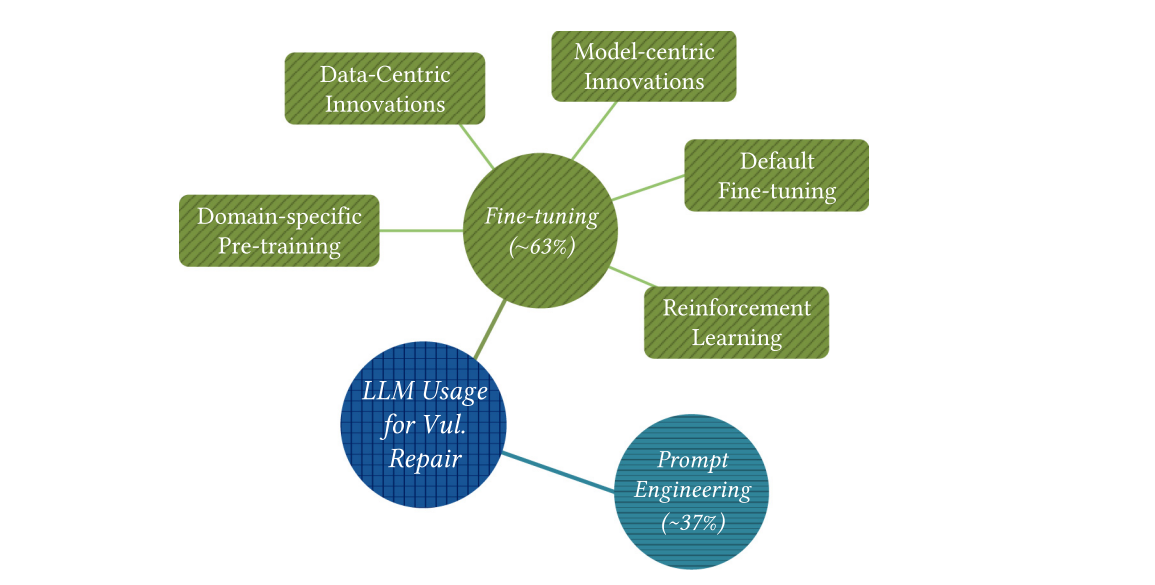 RQ3 sorusuna yanıt:
LLM’lerin güvenlik açığı onarımına uyarlanmasında yaygın olarak kullanılan iki temel teknik mevcuttur: ince ayar (fine-tuning) (≈%63) ve istem mühendisliği (prompt engineering) (≈%37).
RQ3 sorusuna yanıt:
LLM’lerin güvenlik açığı onarımına uyarlanmasında yaygın olarak kullanılan iki temel teknik mevcuttur: ince ayar (fine-tuning) (≈%63) ve istem mühendisliği (prompt engineering) (≈%37).
RQ4 - LLM tabanlı güvenlik açığı tespiti ve onarımı çalışmalarında kullanılan veri kümelerinin ve dağıtım stratejilerinin özellikleri nelerdir?
Önceki araştırma soruları (RQ’lar) öncelikle model oluşturma aşamasına odaklanmaktadır. Bu araştırma sorusunda ise, kullanılan veri kümelerinin özelliklerini ve LLM tabanlı güvenlik açığı tespiti ve onarımı çalışmalarında uygulanan dağıtım stratejilerini incelemeye odaklanılmıştır. Analiz aşağıdaki kriterlere göre gerçekleştirilmiştir.Veri Özellikleri (Data Characteristics)
Dağıtım Stratejileri (Deployment Strategies)
Teşekkürler (AkkuS)