Konular:
- Problem Tanımı
- Veri Kaynakları: Exploit-DB + CVE Zenginleştirme
- Knowledge Base (KB) Tasarımı ve Temizleme/Normalize
- Sentetik ModSecurity Audit Log Üretimi
- Audit Log Parse: Transaction (txid) ve HTTP İstek Çıkarımı
- Özellik (Feature) Çıkarımı: Sayısal + Metin
- Label Üretimi Stratejisi ve “UNKNOWN” Mantığı
- Top1 Dataset ve Binary Dataset (Exploit Var/Yok)
- Modelleme: Çoklu Algoritma Karşılaştırması
- Hata Senaryoları, “Leakage” Riskleri ve Sağlamlaştırma
- Sahada Kullanım: Üretim Trafiğine Uyum ve Kısıtlar
- Sonraki Adımlar: Performans + Gerçek Trafikle Validasyon
Proje Özeti
Bu blog yazısında, Exploit-DB tabanlı bir Knowledge Base (KB) oluşturarak, bu KB’den gerçek ModSecurity audit.log formatına benzeyen sentetik HTTP transaction logları üretme ve sonrasında bu loglardan elde edilen veriler ile Makine Öğrenmesi (ML) kullanarak “Exploit var / Exploit yok” sınıflandırması yapma sürecini uçtan uca anlatıyorum.
Hedefimiz şuydu: Elimizde sınırlı sayıda gerçek log olduğunda bile, gerçekçi ve kontrol edilebilir bir eğitim verisi üretmek; bunun üzerinden “bu istek saldırı mı değil mi?” kararını otomatikleştirmek. Proje ilerledikçe, doğrudan “hangi exploit-id?” sınıflandırmasının çok sınıflı ve veri dağılımı açısından zor olduğunu gördük. Bu nedenle, pratik ve sahada işe yarar bir hedefe odaklandık:
1) Önce Binary Sınıflandırma: Exploit var/yok
2) Exploit varsa: (ID + başlık) gibi metadata’yı raporlamak (bu kısım modelin kendisiyle veya KB eşleştirme ile yapılabilir)
Problem Tanımı
WAF/IDS/IPS tarafında en yaygın operasyonel problem, yüksek hacimli HTTP trafiği içinden saldırı olasılığı yüksek istekleri ayıklamaktır. ModSecurity gibi sistemler kural tabanlı yaklaşımlarla güçlüdür; ancak:
- Yeni saldırı yüzeyleri ve “varyant” istekler kural tabanını zorlar
- Yanlış pozitif/negatif (FP/FN) dengesi operasyonu yorar
- ML yaklaşımı, doğru özellik temsili ile “genelleme” avantajı sağlayabilir
Bu projede, ML yaklaşımını “sıfırdan” kurabilmek için kritik bir sorun vardı: etiketli veri yok veya çok az. Bu yüzden sentetik veri üretimi ile kontrollü bir şekilde eğitim datası hazırladık.
Veri Kaynakları
Exploit-DB ve CVE Zenginleştirme
İki ana kaynak kullandık:
Exploit-DB: exploit açıklamaları, PoC kodları, etkilenen ürün bilgileri, bazen path/endpoint ipuçları
CVE (opsiyonel zenginleştirme): CVE açıklamaları üzerinden ek path/payload ipuçları
Bu içerik “ham metin” olduğu için doğrudan kullanılabilir değildir. Özellikle exploit metinlerinde:
- IP adresleri, domainler, sosyal medya linkleri
- XML/soap namespace’leri (endpoint sanılabilir ama değil)
- Header value’ları (Accept gibi) endpoint sanılabilir
- Dosya yolları (///etc/shadow gibi) gerçek HTTP endpoint değil (web yüzeyi ile karışabilir)
Bu yüzden KB oluşturma adımında, endpoint çıkarımını agresif filtreler ile temizledik ve “gerçek HTTP path” olma ihtimali düşük her şeyi ayıkladık.
Knowledge Base (KB) Mimari Tasarımı
1) KB Üretimi: pipeline.build_exploit_kb
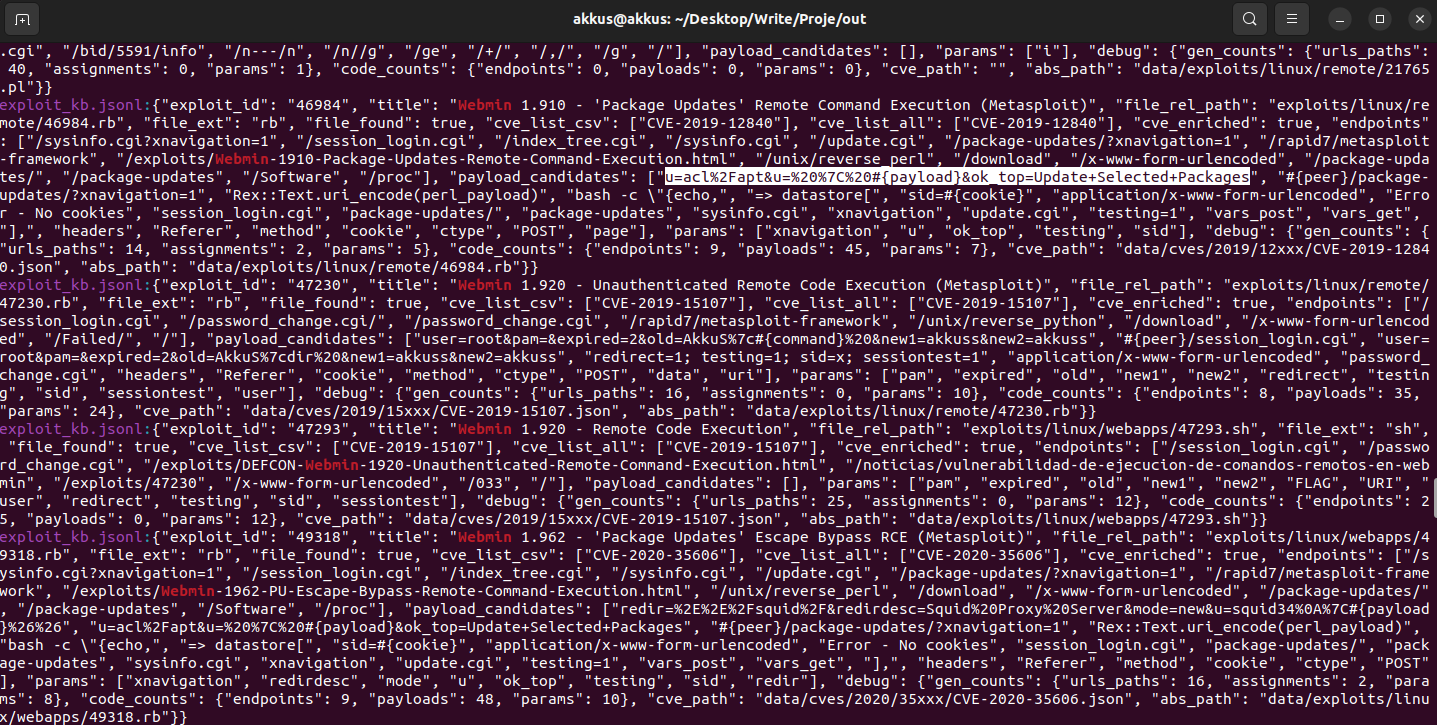
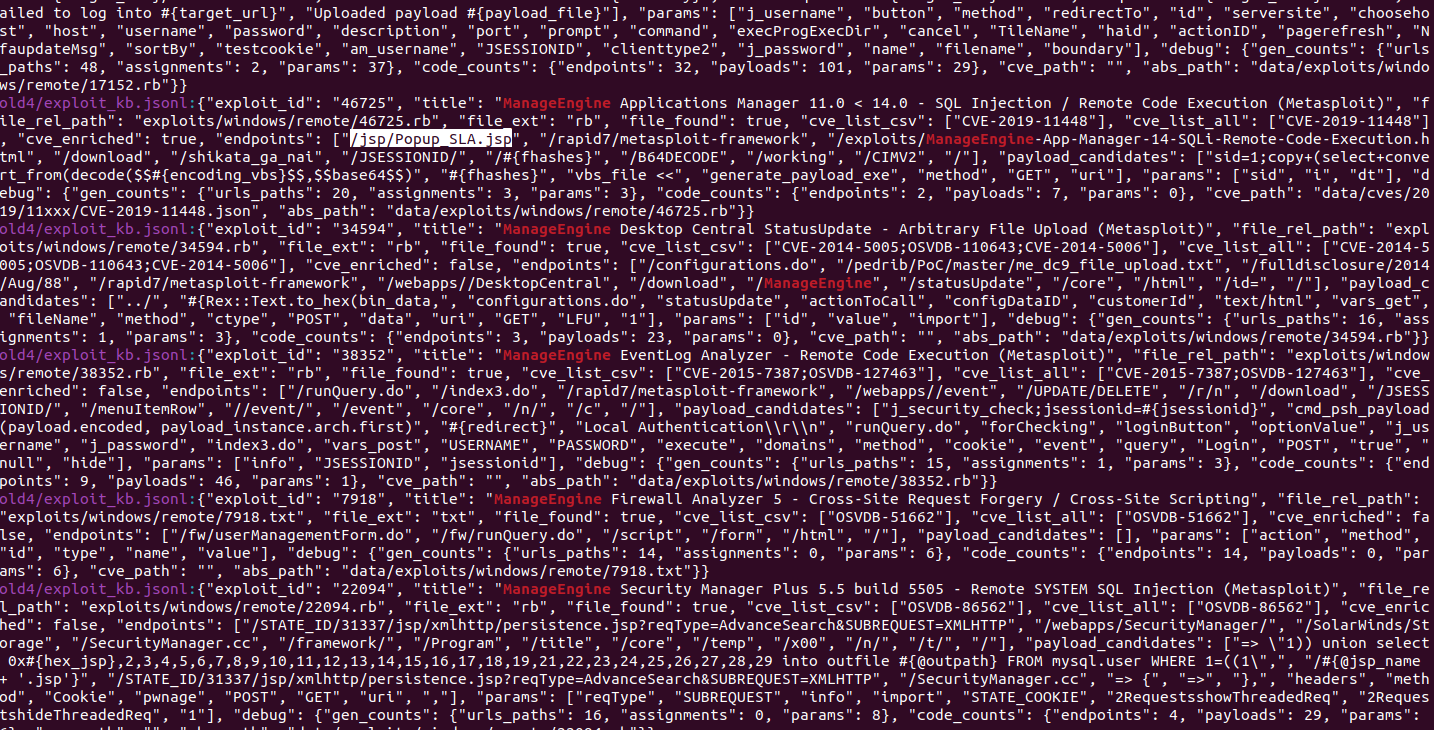
Bu adımın amacı, Exploit-DB içeriğini “modelin anlayacağı” yapılandırılmış formata dönüştürmektir. Çıktı JSONL formatındadır (her satır bir kayıt).
KB’de hedeflediğimiz temel alanlar:
- exploit_id: benzersiz kimlik (Exploit-DB ID)
- title: exploit başlığı
- cve: varsa CVE id
- endpoints: olası HTTP path listesi (temizlenmiş)
- params: olası query/body parametre isimleri
- payloads: olası payload parçaları (sadece web ile ilişkili olanlar)
- raw_text: geri izlenebilirlik için ham içerik (opsiyonel)
Bu adımda kritik kalite metriği şudur: “endpoints” alanı ne kadar doğru/temiz ise sonraki aşamalar o kadar sağlıklı çalışır.
2) KB Signature/Normalize: pipeline.kb_signatures
Bu adım, ham KB kayıtlarını daha “eşleştirme dostu” hale getirir. Yani:
- Endpoint’leri normalize eder (ör: URL şeması/host varsa ayıklar, path’e indirger)
- Parametre isimlerini ayrıştırır, sadeleştirir
- Basit “primitive” imzalar üretir (ör: path + param set + payload ipuçları)
- “web surface” kavramını çıkarır: bir exploit gerçekten web endpoint/payload içeriyor mu?
Not: “require-web” filtreleri bu işaretlemeye göre çalışır. Eğer KB’de “web surface” yanlış işaretlenirse, sonraki sentetik üretim adımı “No KB records available after filtering” hatasına gidebilir. Bu nedenle KB temizliği ve signature üretimi en kritik katmandır.
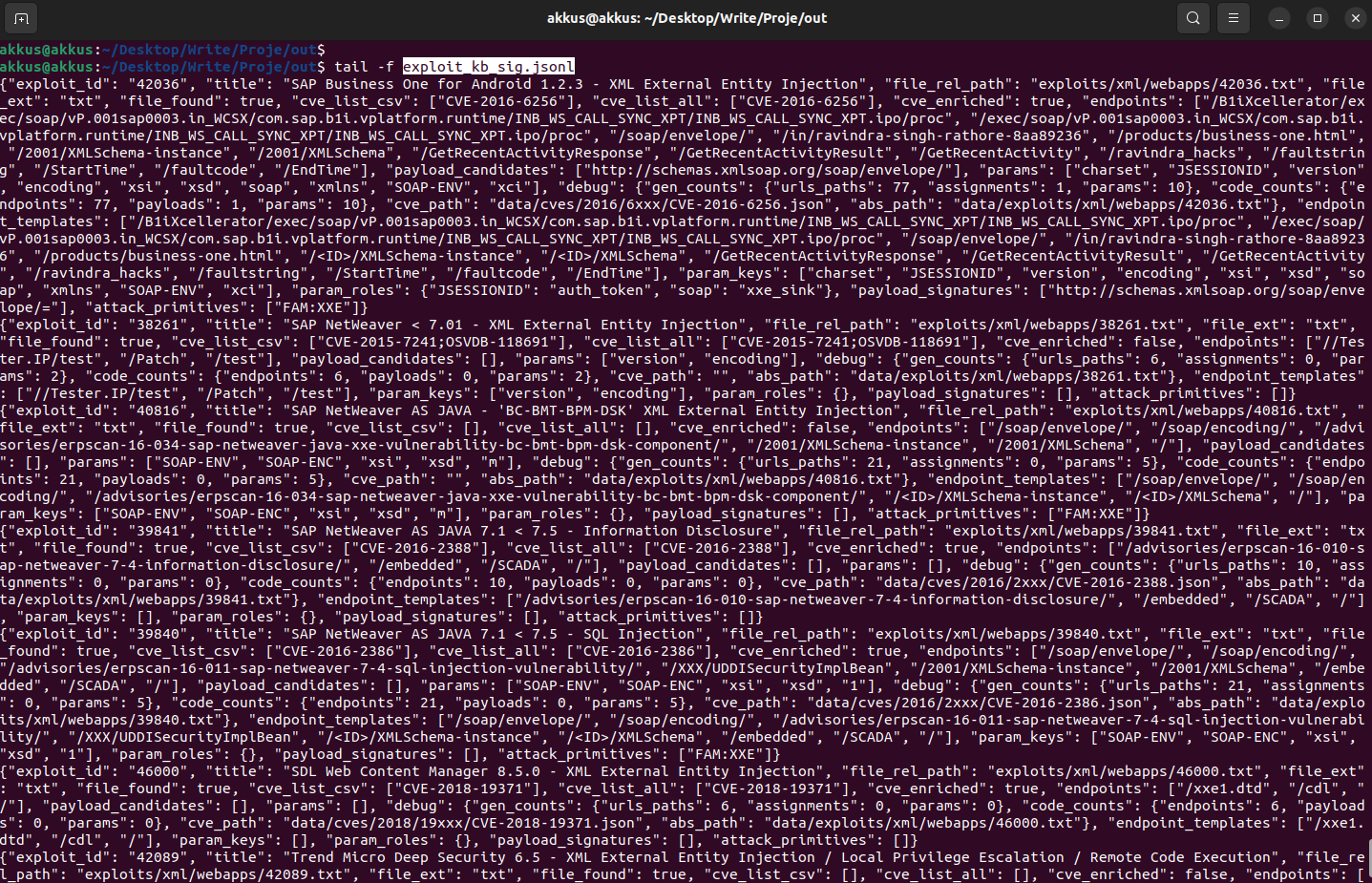
Sentetik ModSecurity Audit Log Üretimi
3) pipeline.render_modsec_audit_from_kb
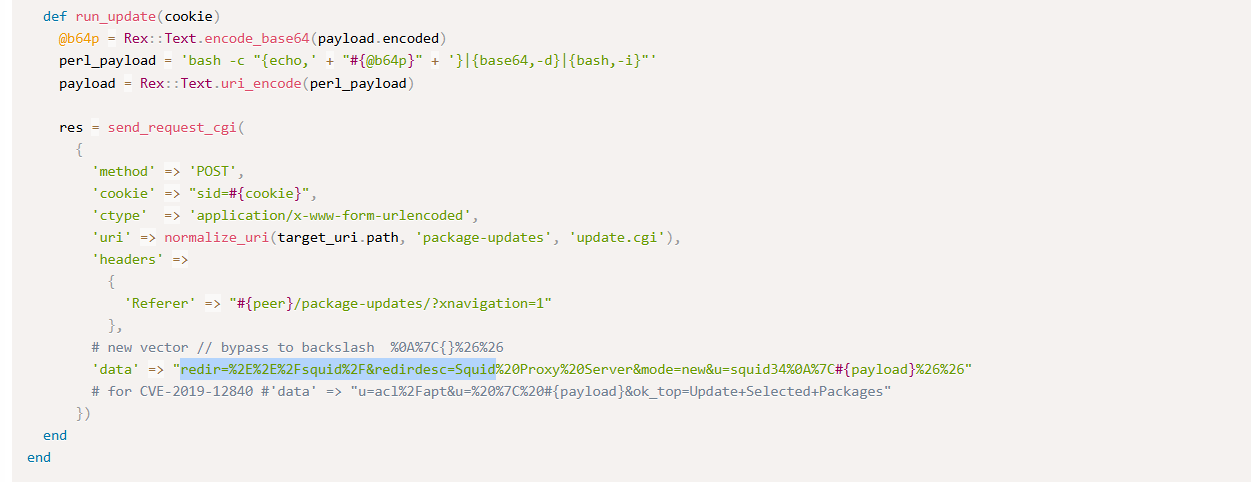
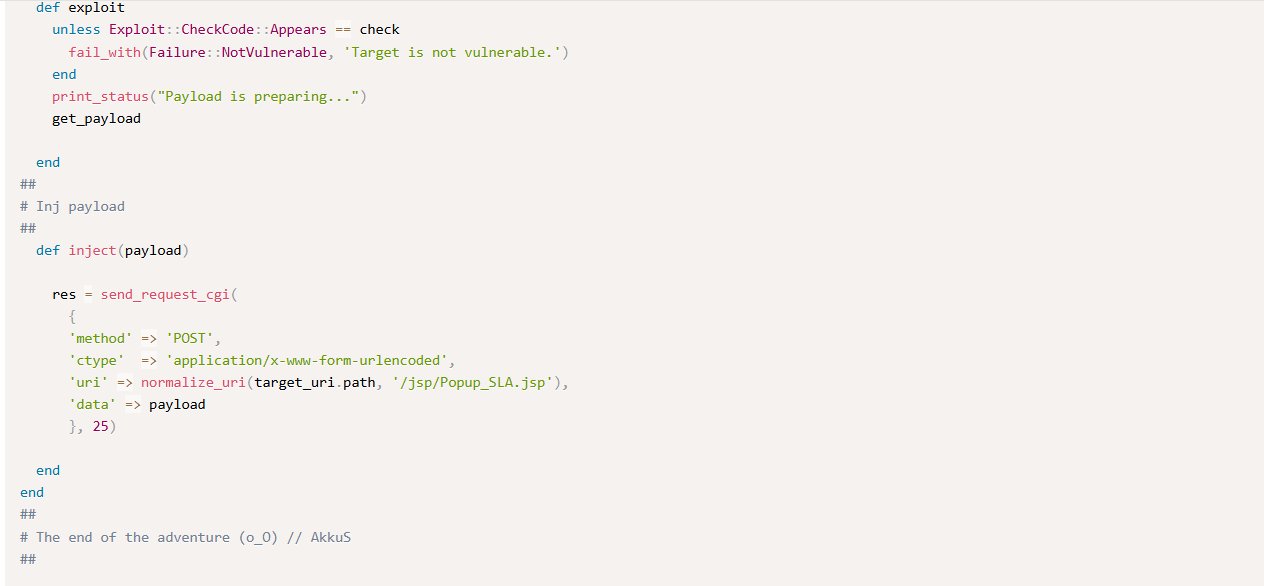
Bu adım, KB’den ModSecurity audit.log’a benzer transaction blokları üretir. Amaç “gerçek sistemde saldırı yapılmış gibi” log elde etmektir.
Üretimde iki trafik türü vardır:
(A) Attack Trafiği: KB’deki exploit kayıtlarından türetilen istekler
(B) Benign(yararlı) Trafik: normal kullanıcı davranışını temsil eden örnek istekler (GET /, arama parametreleri, basit form postları vb.)
Bu iki trafik aynı log dosyası içinde karışık durur. Böylece model “sadece saldırı örneklerini” değil, gerçek hayatta sürekli gelen normal trafiği de görür.
Örnek parametreler:
- --n-exploits / --n: kaç farklı exploit seçilecek (veya toplam exploit örnek sayısı)
- --per-exploit: her exploit için kaç saldırı transaction’ı üretilecek (class-balance için kritik)
- --benign-ratio: benign oranı (ör: 0.35 = %35 civarı benign)
- --require-web: sadece web yüzeyi belirgin exploitleri seç (KB’de web surface yoksa filtreler)
- --host: log içinde görünen host değerini sabitlemek (örn. 127.0.0.1)
Burada önemli bir not: Biz gerçek sunucuya saldırı göndermiyoruz. Sadece log formatını simüle ediyoruz. Bu yaklaşım hem etik hem güvenlik açısından doğru; ayrıca “kontrollü veri üretimi” avantajı sağlar.
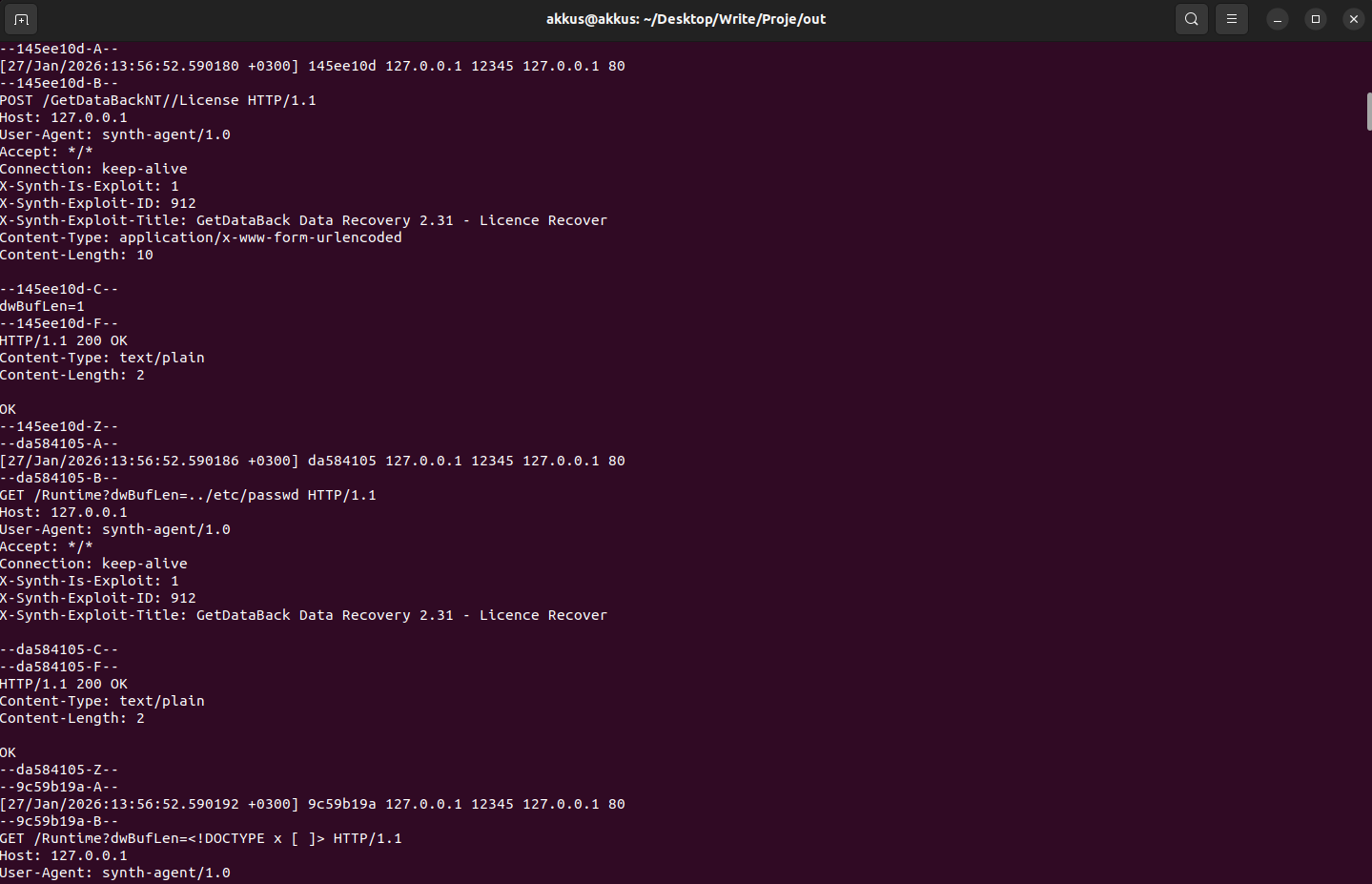
Audit Log Parse: Transaction ve HTTP İstek Çıkarımı
4) pipeline.parse_modsec_audit
ModSecurity audit logları tek satır “access log” gibi değildir; transaction bazlı bloklar içerir (A/B/C/D/E/F/H/Z benzeri bölümler). Bu adım, log dosyasını okuyup transaction (txid) temelinde her isteği ayrıştırır.
Çıktı JSONL formatında “request” kayıtlarıdır. Tipik alanlar:
- txid: transaction id (aynı request’i uçtan uca bağlar)
- method: GET/POST/PUT…
- path: /login, /api/v1/… gibi endpoint
- query: varsa query string
- headers: request header isimleri (opsiyonel: değerler)
- body: request body (form/json/xml) (opsiyonel truncate)
Parse kalitesi, feature ve text alanlarını doğrudan etkiler. Bu yüzden parse edilen “path” ve “body” gibi alanların doğru oluşması ML performansı için kritiktir.
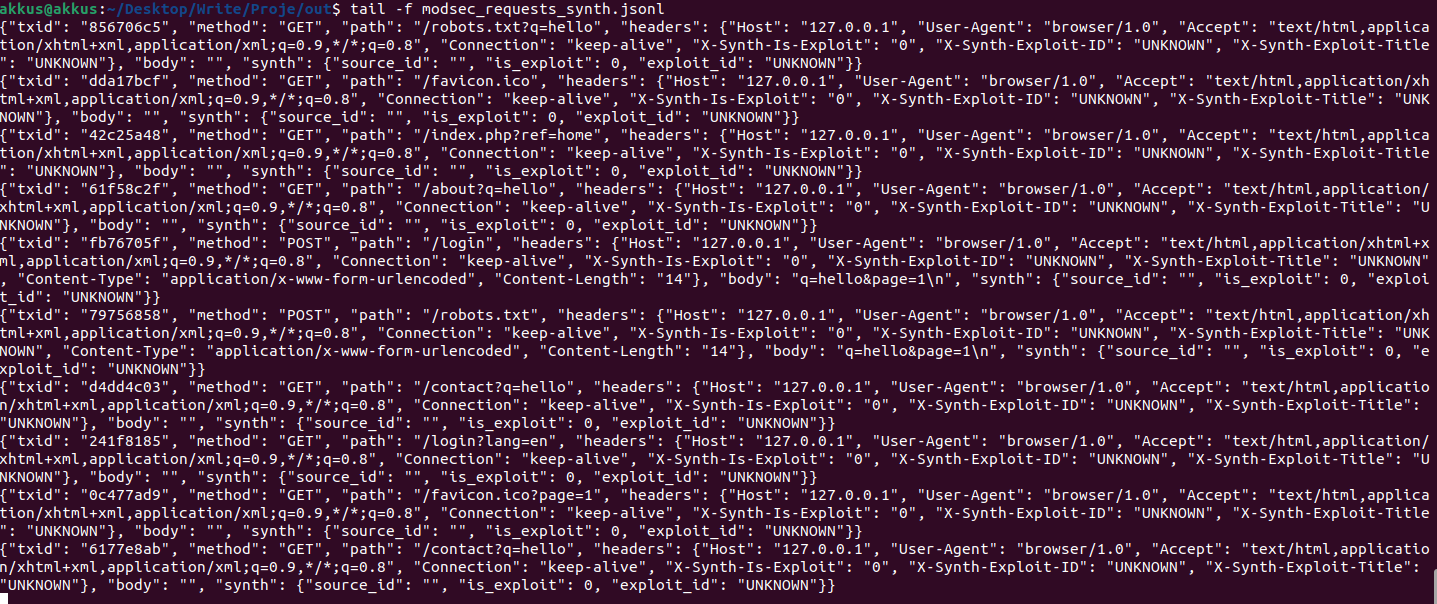
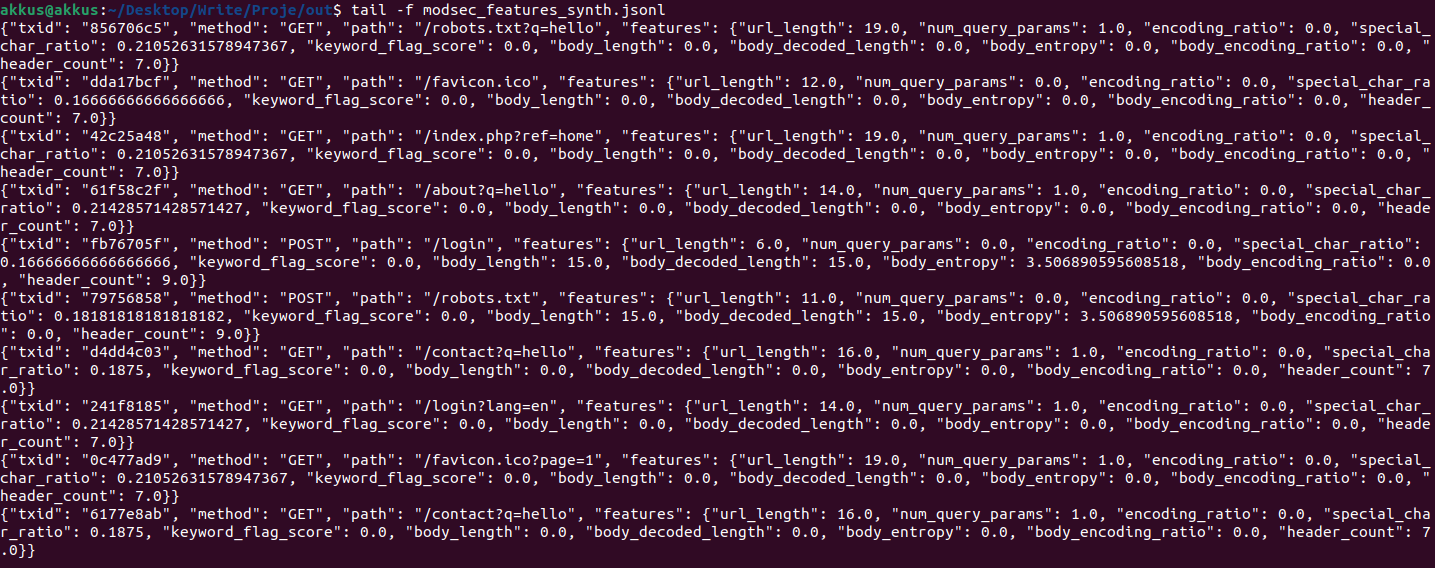
Özellik Çıkarımı
5) pipeline.extract_request_features
Bu adım, her request’ten sayısal feature vektörü çıkarır. Örnekler:
- url_length: path+query uzunluğu
- num_query_params: query param sayısı
- special_char_ratio: özel karakter oranı (payload göstergesi olabilir)
- encoding_ratio: URL encoding yoğunluğu
- keyword_flag_score: SQLi/XXE/LFI gibi anahtar kelime sinyali
- body_length / body_entropy: body boyutu ve entropisi (rastgele/payload yoğunluğu sinyali)
- header_count: header sayısı
Buradaki yaklaşım şudur: “text olmadan bile” belirli saldırı sınıfları yapısal olarak farklı iz bırakır. Ancak pratikte en iyi sonuç genellikle text + numeric birleşimi ile gelir.
Text Temsili (method/path/headers/body)
Binary sınıflandırmada özellikle “path” ve “body” çok kıymetlidir. Bu nedenle eğitim dataset’ine isteğe bağlı olarak şu text alanlarını ekledik:
- method (GET/POST)
- path (/admin/login vs.)
- headers (sadece isimler veya isim+değer)
- body (truncate edilmiş)
Bu text, daha sonra ML tarafında n-gram ile vektörleştirilir.
Label Üretimi (Saldırı mı Değil mi?)
İki farklı label yaklaşımı var:
(1) KB Eşleştirme (match_requests_to_kb_v3): request yüzeylerini KB imzalarıyla kıyaslayıp “hangi exploit adayı?” üretir.
(2) Sentetik Üretim Kaynağından Doğrudan Etiket: log üretirken hangi request’in hangi exploit’ten geldiğini zaten biliyoruz; bunu güvenli bir şekilde dataset tarafında kullanırız.
Gerçek hayatta (üretim trafikte) (2) yoktur; ama sentetik veri üretiminde “ground-truth” üretmek için (2) kullanmak normaldir. Burada kritik uyarı: Bu “ground-truth” bilgisi modelin input’una karışmamalı. Yani model, etiket bilgisini feature olarak görmemeli.
Bu yüzden sentetik tarafta “debug/izleme” amaçlı bazı alanlar üretilse bile, ML dataset’ine girerken bunlar kesinlikle feature olarak kullanılmaz.
Top1 Dataset ve Binary Dataset
6) pipeline.build_training_dataset_v2
Bu adım, parse + feature çıktısını birleştirip “train_top1.csv” üretir. Bu CSV’de her satır bir transaction/request karşılığıdır.
Önemli seçenekler:
- --requests: text alanlarını üretebilmek için gerekli
- --features: sayısal feature’lar burada
- --labels: (varsa) exploit-id/başlık gibi label kolonlarını buradan alır
- --text-cols: hangi text alanları eklenecek (method path headers body)
- --no-header-values: header değerlerini çıkartıp sadece isimleri bırakır (leakage azaltır, boyutu düşürür)
- --drop-zero-variance: tüm dataset boyunca sabit kalan useless feature’ları çıkarır
7) pipeline.build_training_dataset_top1_binary
Bu adım, “train_top1.csv” dosyasından binary hedef üretir:
- is_exploit = 1 → label_exploit_id != UNKNOWN
- is_exploit = 0 → label_exploit_id == UNKNOWN
Ayrıca “exploit varsa” raporlamak için:
- label_exploit_id
- label_title
kolonlarını korur. Bu sayede model “exploit var/yok” kararını verir; exploit varsa biz aynı satırdan ID ve başlığı UI/rapor tarafında gösterebiliriz.

Modelleme: Binary Benchmark
8) pipeline.ml_benchmark_binary_top1
Bu adımda hedef, farklı algoritmalarla hızlı bir karşılaştırma yapmaktır. Klasik algoritma listemiz:
LR, LDA, KNN, DT, NB, SVM, RF, GBC
İki mod vardır:
(A) Sadece Numeric: hızlı, daha sınırlı sinyal
(B) Text + Numeric: daha güçlü sinyal (n-gram), ama bazı modeller sparse matriste iyi çalışır (LR, LinearSVC, SGD gibi)
KNN’nin çok uzun sürmesinin sebebi basittir: KNN “eğitim”de model öğrenmez; tahmin anında her örneği tüm eğitim verisiyle kıyaslar. Bu yüzden test zamanı büyür (O(N) veya daha kötü). Büyük dataset’lerde KNN pratik değildir ve çıkarılması mantıklıdır.
Benchmark çıktısında baktığımız metrikler:
- Accuracy (genel doğruluk)
- Precision/Recall/F1 (özellikle exploit=1 sınıfı için kritik)
- Confusion Matrix (TP/FP/FN/TN)
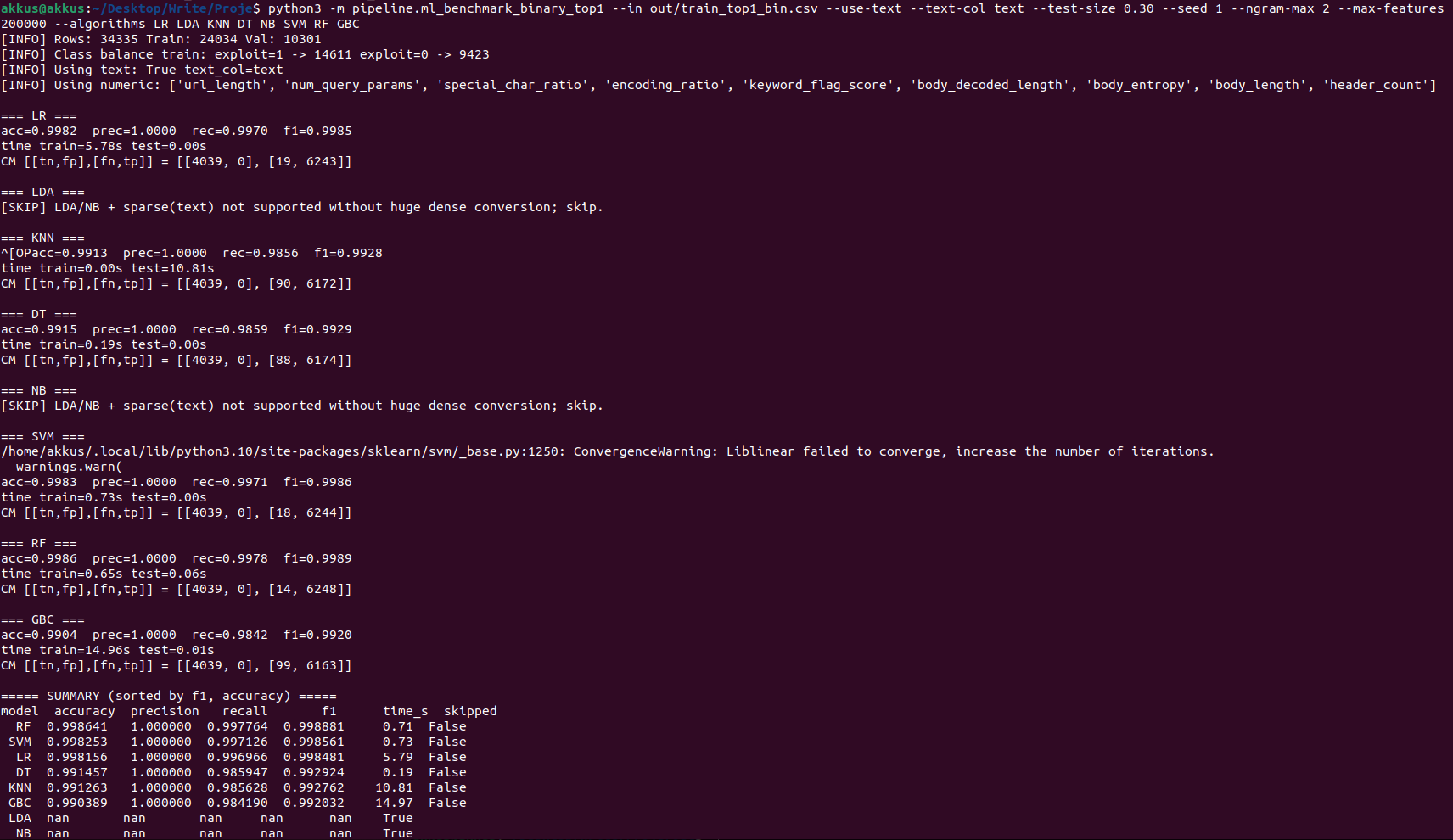
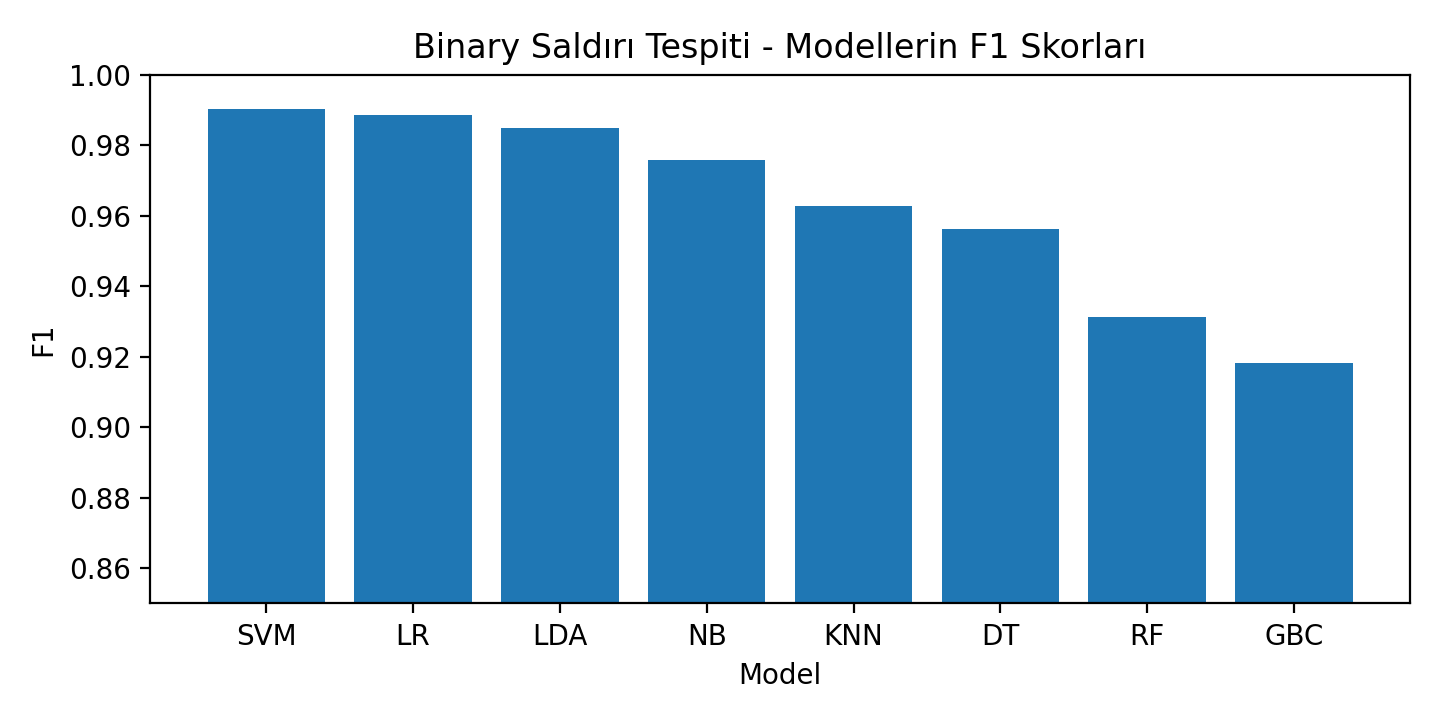
===== SUMMARY (sorted by f1, accuracy) =====
model accuracy precision recall f1 time_s skipped
SVM 0.987267 0.984764 0.995599 0.990152 0.092858 False
LR 0.985233 0.988180 0.988860 0.988520 2.402891 False
LDA 0.980635 0.982353 0.987622 0.984980 6.366140 False
NB 0.968079 0.954247 0.998212 0.975734 0.012003 False
KNN 0.951985 0.958936 0.966717 0.962811 16.218175 False
DT 0.941993 0.927270 0.987209 0.956302 5.420588 False
RF 0.911929 0.935824 0.926558 0.931168 0.525235 False
GBC 0.895835 0.926501 0.910191 0.918274 1.442294 False
Kalite Kontrol, Leakage Riskleri ve Neden “%100” Görülebilir?
Bazı çalıştırmalarda neredeyse %100’e yakın sonuçlar görülebilir. Bu her zaman “mükemmel model” demek değildir. İki büyük risk var:
1) Etiket sızıntısı (label leakage): Eğer text içine veya feature’lara “etiketi ele veren” bir şey girerse model sahte başarı yapar. Örn: Sentetik üretimde debug amaçlı eklenen bir header veya sabit bir pattern, sadece saldırılarda bulunuyorsa model bunu ezberler.
2) Sentetik veri dağılımı: Benign örnekler çok tek tip, saldırılar çok farklı/tek tip üretilmiş olabilir. Model “sentetik generator’ı” öğrenir.
Bu yüzden:
- Sentetik “ground-truth” bilgileri feature’a sokmuyoruz
- Benign (iyi huylu) üretimini çeşitlendiriyoruz (GET/POST, farklı param setleri, farklı path’ler)
- Header/value gibi alanlarda “sabit” artefakt oluşmasını engelliyoruz
- Mümkünse küçük bir gerçek log seti ile “final sanity check” (Akıl Sağlığı Kontrolü) yapıyoruz
Çalıştırma Akışı (Tek Parça Komut Listesi)
Aşağıdaki akış, projeyi temiz şekilde baştan sona çalıştırmak içindir. (Yorum satırları açıklamadır.)
# 1) Exploit-DB + CVE kaynaklarından ham Knowledge Base oluşturma
python3 -m pipeline.build_exploit_kb \
--files-csv data/files_exploits.csv \
--exploits-root data/exploits \
--cves-root data/cves \
--out out/exploit_kb.jsonl
# 2) KB kayıtlarını normalize etmek + signature çıkarmak (endpoint/param/payload yüzeyleri)
python3 -m pipeline.kb_signatures \
--in out/exploit_kb.jsonl \
--out out/exploit_kb_sig.jsonl
# 3) KB’den ModSecurity audit.log formatında sentetik trafik üretme
# - Ground-truth yani Gerçek durum header’ları ekleme ( Örn. X-Synth-Exploit-ID: 30515, X-Synth-Is-Exploit: 1 )
python3 -m pipeline.render_modsec_audit_from_kb \
--kb out/exploit_kb_sig.jsonl \
--out out/modsec_audit_synth.log \
--seed 1 \
--n-exploits 5000 \
--per-exploit 5 \
--benign-ratio 0.35 \
--host 127.0.0.1 \
--with-ground-truth-headers
# 4) ModSecurity audit log → request transaction JSONL parse / ModSecurity audit log içinden HTTP request transaction’larını parse etme
python3 -m pipeline.parse_modsec_audit \
--in out \
--out out/modsec_requests_synth.jsonl
# 5) Request’lerden sayısal feature çıkarma (URL/body/header istatistikleri)
python3 -m pipeline.extract_request_features \
--in out/modsec_requests_synth.jsonl \
--out out/modsec_features_synth.jsonl
# 6) TOP1 dataset üretme (X-Synth-* header’lardan is_exploit türetilir.)
# - text alanını method/path/headers/body ile oluşturma
# - --no-header-values: header değerlerini değil sadece isimlerini yazma (Burada modelin “ezber” riski azaltılmaktadır.)
python3 -m pipeline.build_training_dataset_v2 \
--features out/modsec_features_synth.jsonl \
--requests out/modsec_requests_synth.jsonl \
--out-top1 out/train_top1.csv \
--unknown-id UNKNOWN \
--drop-zero-variance \
--max-text-len 2000 \
--text-cols method path headers body \
--no-header-values
# 7) train_top1 → binary dataset oluşturma (is_exploit 0/1)
python3 -m pipeline.build_training_dataset_top1_binary \
--in out/train_top1.csv \
--out out/train_top1_bin.csv \
--unknown-id UNKNOWN \
--keep-text \
--drop-zero-variance
# 8) Binary benchmark: dataset ile tüm algoritmaları çalıştırma
python3 -m pipeline.ml_benchmark_binary_top1 \
--in out/train_top1_bin.csv \
--use-text \
--text-col text \
--test-size 0.30 \
--seed 1 \
--ngram-max 2 \
--max-features 200000 \
--algorithms LR LDA KNN DT NB SVM RF GBC
Canlı Uygulama
Teşekkürler. // Özkan Mustafa AKKUŞ & Mehmet Akif GÖZÜM